
Thesis
Evaluating the Effectiveness of Feature Extraction Methods in Spam and Phishing Classification
Supervisor
Thesis: Bachelor’s/Master’s Thesis
Spam and phishing attacks are still a problem in today’s digital communication, costing individuals and organizations billions annually. Detecting these threats effectively requires robust (machine learning) models, but the performance of these models heavily depends on how we represent the text data. And this is where feature extraction comes into play.
This thesis explores how different feature extraction techniques, such as chargrams, single words, and sentence embeddings, impact the effectiveness of spam and phishing detection. By comparing their strengths, weaknesses, and performance, we aim to identify which methods work best for specific scenarios and why.
What You’ll Do
- Experiment with feature extraction techniques: Implement and evaluate methods like n-grams, word embeddings, and sentence-level representations (see Figure 1).
- Build and compare models: Train traditional and/or ML-based classifiers (e.g., Naive Bayes, SVMs, Neural Networks) using these features and analyze their performance.
- Identify trade-offs: Understand and compare the computational cost, interpretability, and accuracy of each approach.
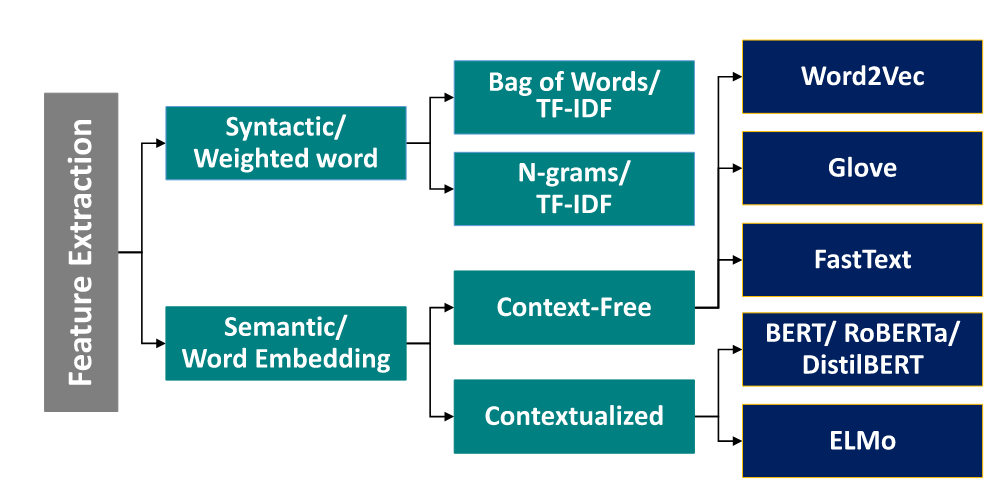
Figure 1: A selection of feature extraction methods (Salman et al., 2024)
Prerequisities
Required
- Basic understanding of machine learning and articifial intelligence (finished the course Foundations of Artificial Intelligence)
- Familiarity with Natural Language Processing techniques, e.g., text classification and feature extraction techniques
- Proficiency in at least one programming language (preferably Python)
Optional
- You took the following courses:
- Internettechnologies & Web Engineering
- Advanced Methods of Machine Learning
- Security in Communication Networks
- Familiarity with evaluation metrics for AI models
- Proficiency in using LaTeX