Evonik Digital Research
A joined research project with University Duisburg-Essen
A joined research project with University Duisburg-Essen
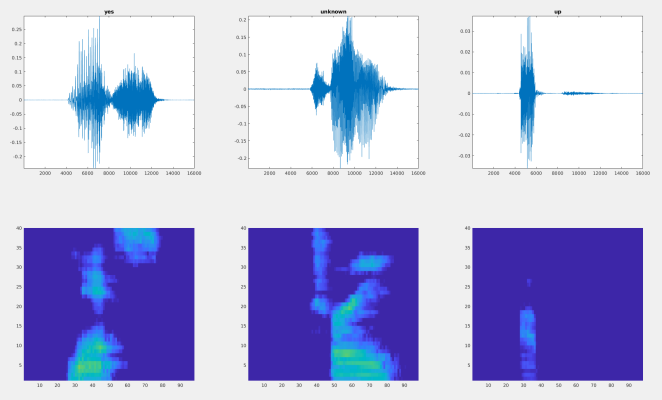
In this part of work, a deep convolutional neural network was optimized and trained for sound classification. The work in this section belongs to supervised learning. We converted audio clips into spectrograms and imported them into the deep convolutional neural network to distinguish between explosions and non-explosions. This part of the work is divided into three steps:
Finally, the classification accuracy of this neural network for training set is about 91%. We used 50 explosion fragments and 50 non-explosion fragments as a test set. The data in the test set were not used in the training procedure. For the neural network, these data were totally new.
The Confusion Matrix shows the quality of the detection. In the experiment, among 50 explosive sound fragments, 39 of them were classified correctly as such type. Among 50 non-explosive sounds, all 50 of them are classified correctly as such type.